Gunicorn Workers vs. Threads: An Overview for Python Apps

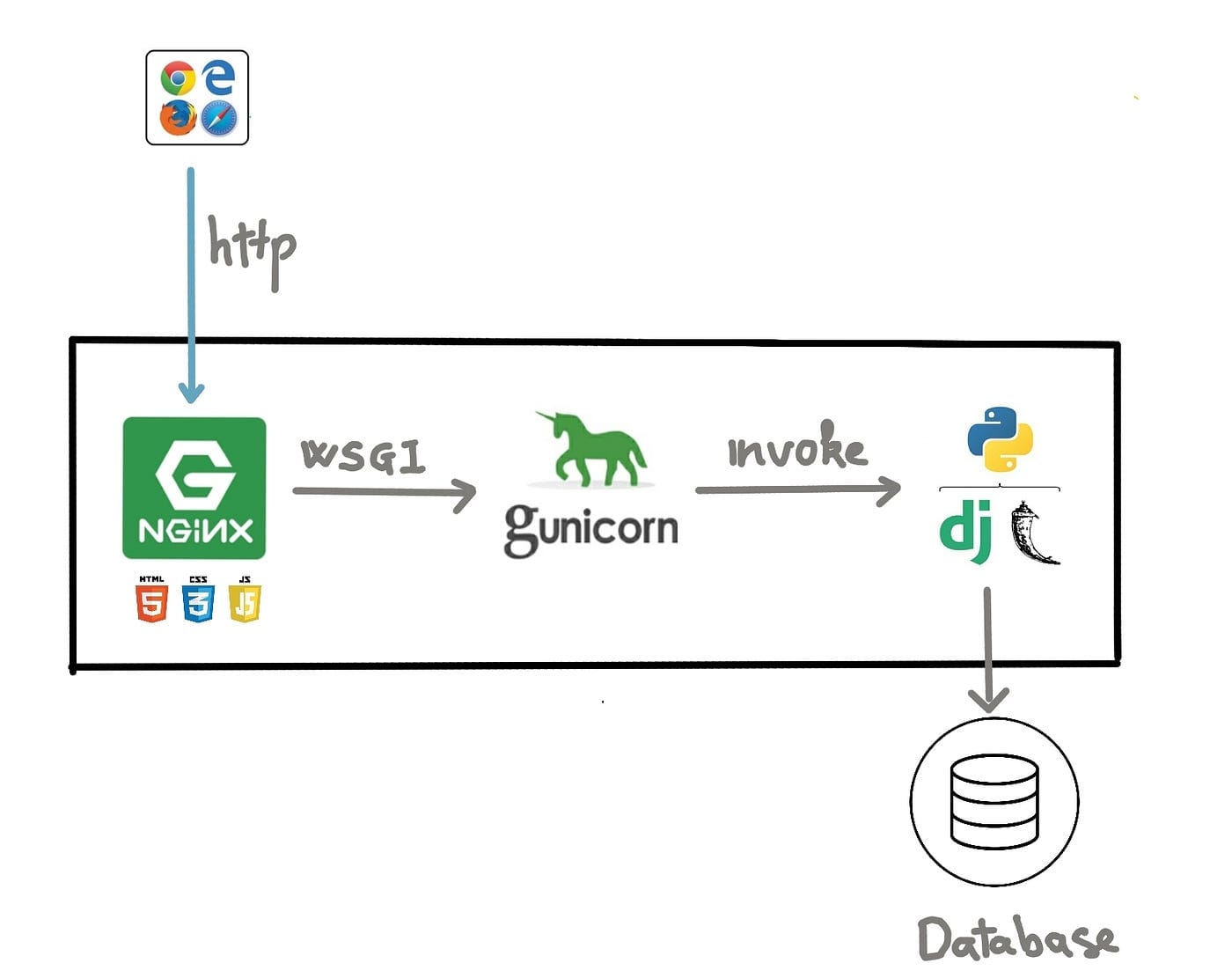
Deploying a Python web app? Gunicorn is a go-to WSGI server, but its performance hinges on how you configure workers and threads. Misconfigure them, and your app could crawl under load—or worse, crash unpredictably.
In this guide, we’ll break down:
- When to use workers vs. threads (and why it matters).
- Hybrid setups (workers + threads).
- Async alternatives (
gevent,eventlet). - Pro tips for benchmarking and avoiding pitfalls.
Let’s dive in.
1. Workers: Process-Based Isolation - The Heavy Lifters
What Workers Really Are
Workers are independent operating system processes that each run a complete copy of your Python application. Unlike threads, which share memory space, workers are completely isolated from each other at the OS level. This means:
- Each worker has its own Python interpreter instance
- Each maintains separate memory space (heap, stack, etc.)
- Each handles requests independently of others
When you run Gunicorn with --workers 4, you're essentially launching 4 separate Python processes that all happen to be running the same WSGI application.
When Workers Shine
✅ CPU-bound workloads:
Workers excel at parallelizing tasks that consume significant CPU resources. For example:
- Machine learning inference (TensorFlow, PyTorch)
- Image/video processing (Pillow, OpenCV)
- Complex data transformations (Pandas, NumPy)
✅ Stability through isolation:
If one worker crashes due to:
- A memory leak
- An unhandled exception
- A segfault in a C extension
...the other workers continue running unaffected. This makes your application more resilient to failures.
✅ True parallelism (GIL avoidance):
Each worker has its own Global Interpreter Lock (GIL), allowing Python code to execute simultaneously across multiple CPU cores. This is crucial for achieving actual parallelism in Python applications.
The Tradeoffs You Need to Understand
❌ Memory overhead:
Every additional worker means:
- Another copy of your application in RAM
- Another copy of your static data
- Another copy of any imported libraries
For large applications, this can quickly consume available memory. A 500MB Django app with 4 workers needs ~2GB RAM just for the workers.
❌ No shared memory:
Workers can't directly share:
- In-memory caches (like
@lru_cachedecorators) - Global variables
- In-process session stores
This means if you implement caching at the application level, each worker maintains its own separate cache.
Advanced Configuration Tips
Starting Point Formula
# Dynamically calculates workers based on CPU cores
gunicorn --workers $((2 * $(nproc) + 1)) app:wsgiThis classic formula (2n+1) provides:
- n workers for CPU utilization
- n workers for I/O wait
- 1 extra worker as buffer
But treat this as a starting point, not gospel truth.
Memory Optimization Techniques
- Preloading (
--preload):
gunicorn --workers 4 --preload app:wsgi- Loads the app once before forking workers
- Uses copy-on-write memory sharing
- Warning: Can cause issues with:
- Database connections
- File handles
- Other resources that don't fork cleanly
- Worker recycling (
--max-requests,--max-requests-jitter):
gunicorn --workers 4 --max-requests 1000 --max-requests-jitter 50 app:wsgi- Automatically restarts workers after N requests
- Helps mitigate memory leaks
- Jitter prevents all workers restarting simultaneously
Real-World Example: Image Processing Service
Consider an image thumbnail generation service:
# app.py
from PIL import Image
def generate_thumbnail(image_path):
img = Image.open(image_path)
img.thumbnail((300, 300))
return imgHere, workers are ideal because:
- PIL/Pillow operations are CPU-intensive
- No need for shared state between requests
- Crash isolation prevents one bad image from taking down the whole service
Configuration might look like:
gunicorn --workers $(nproc) --preload --max-requests 500 app:wsgi2. Threads: Lightweight Concurrency
Threads provide concurrency within a single process. Unlike workers:
- All threads share the same memory space
- They're much lighter weight than processes
- They're managed by the operating system's thread scheduler
This makes threads ideal for I/O-bound applications where most time is spent waiting for external resources (databases, APIs, file systems). However, Python's Global Interpreter Lock (GIL) means that only one thread can execute Python bytecode at a time, limiting their effectiveness for CPU-bound tasks.
Thread programming also introduces complexity around shared state. Without proper synchronization, race conditions can lead to subtle, hard-to-reproduce bugs.
When to Use Threads
- ✅ I/O-bound applications: (APIs, database-heavy workloads)
- ✅ When memory is constrained: (threads share memory space)
- ✅ For applications that need fast inter-task communication
The Gotchas
- ❌ GIL limitations for CPU-bound work
- ❌ Thread safety concerns with shared state
- ❌ Debugging challenges with race conditions
Configuration Tips
# Using threads with Gunicorn
gunicorn --threads 4 app:wsgi
# Combining with workers
gunicorn --workers 2 --threads 4 app:wsgi- Start with 2-4 threads per worker and benchmark
- Use thread-safe libraries and data structures
- Add thread identifiers to your logs for debugging
3. Hybrid Approach: Workers + Threads
The hybrid model combines both approaches:
- Multiple worker processes
- Each worker running multiple threads
This provides a balance between process isolation and memory efficiency. The total concurrency is workers × threads. For example, 3 workers with 4 threads each can handle 12 concurrent requests.
This approach works well for applications with:
- Mixed workload patterns
- Moderate CPU requirements
- Significant I/O waiting periods
However, it combines the complexity of both models, making debugging more challenging.
When It Works Best
- ✔ Applications with both CPU and I/O requirements
- ✔ When you need to maximize resource utilization
- ✔ For gradual scaling between process and thread models
Potential Pitfalls
- ✖ Combined complexity of both models
- ✖ Still subject to GIL limitations
- ✖ Higher potential for deadlocks
Configuration Recommendations
# Typical hybrid configuration
gunicorn --workers 3 --threads 4 app:wsgi- Start with equal workers and threads (e.g., 2 workers × 2 threads)
- Monitor both CPU and memory usage carefully
- Stress test for race conditions
4. Async Workers: gevent and eventlet
Async workers use cooperative multitasking:
- Single process handles many connections
- Uses non-blocking I/O operations
- Achieves high concurrency with low overhead
This model is particularly effective for:
- Applications with many idle connections
- Real-time features like WebSockets
- Extremely I/O-heavy workloads
However, it requires all code in the application to be async-compatible. Any blocking operation can stall the entire worker.
For extreme I/O-bound cases (thousands of connections), async workers can outperform threads:
gunicorn --worker-class gevent --worker-connections 1000When to choose async:
- ✅ Applications with thousands of concurrent connections
- ✅ When using async frameworks like FastAPI
- ✅ For specialized high-concurrency use cases
Challenges to consider:
- ❌ All code must be async-aware
- ❌ Debugging can be more complex
- ❌ Not suitable for CPU-bound tasks
Configuration Example
gunicorn --worker-class gevent --worker-connections 1000 app:wsgi- Start with default settings and increase connections gradually
- Monitor for event loop stalls
- Ensure all dependencies are async-compatible
Benchmarking and Optimization Strategies
Load Testing Approaches
- Baseline testing: Establish performance metrics with default settings
- Incremental changes: Adjust one parameter at a time (workers or threads)
- Real-world simulation: Test with production-like traffic patterns
Key Metrics to Monitor
- Requests per second
- Response time percentiles (especially 95th and 99th)
- CPU utilization per core
- Memory usage per worker
Optimization Workflow
- Start with conservative defaults
- Identify bottlenecks (CPU vs. I/O)
- Adjust configuration accordingly
- Validate with load testing
- Monitor in production
Conclusion and Final Recommendations
Decision Framework
- CPU-bound? → Use workers
- I/O-bound? → Use threads or async
- Mixed workload? → Consider hybrid approach
- Massive concurrency needed? → Evaluate async workers
Pro Tips
- Always benchmark with realistic workloads
- Monitor production behavior continuously
- Document your configuration decisions
Your Turn
What Gunicorn configuration works best for your application? Share your experiences and questions in the comments!